Bigtop 3.2.0 のコンポーネントを Ambari を使ってデプロイする
Apache Bigtop 3.2.0 では, Bigtop が提供する最新のコンポーネント群 (の一部) を Apache Ambari 経由でデプロイできるようになりました。 サポート対象の OS は、残念ながら現時点では CentOS 7 のみとなりますが、試してみましょう。
前提とする環境
以下の5台の CentOS 7 マシンを用意し, ambari サーバに Ambari を, manager に Hadoop の NameNode, ResourceManager を, worker1~3 に同じく DataNode, NodeManager を、それぞれインストールします。
- ambari
- manager
- worker1
- worker2
- worker3
手順
まず, ambari サーバの yum に Bigtop のリポジトリを追加します。 Bigtop の公式サイト を開き、 ページ中央の “Latest release” のリンク先から, “Installable binary artifacts” を選択します。
リンクを辿っていくと、以下のようなファイルの一覧が表示されます。
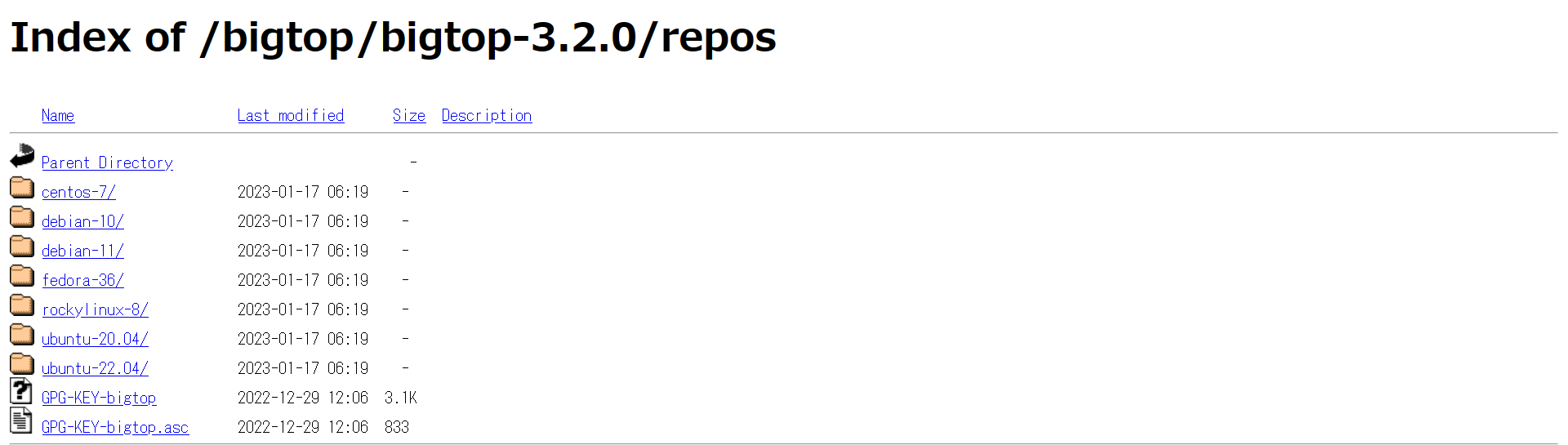
Linux ディストリビューションごとにディレクトリが分かれており、それぞれにリポジトリ情報を定義した設定ファイルが格納されています。 ですので今回は, centos-7 ディレクトリに格納されている設定ファイル bigtop.repo を ambari.repo という名前で取り込みます。 また, Ambari の動作には JDK が必要なので、あらかじめインストールしておきます。
[azureuser@ambari ~]$ sudo yum install -y java-1.8.0-openjdk-devel
[azureuser@ambari ~]$ sudo curl -sL https://dlcdn.apache.org/bigtop/bigtop-3.2.0/repos/centos-7/bigtop.repo -o /etc/yum.repos.d/ambari.repo
設定ファイルを取り込んだら, yum のリポジトリ情報を更新し, Ambari と Bigtop Mpack をインストールします。
[azureuser@ambari ~]$ sudo yum update -y
[azureuser@ambari ~]$ sudo yum install -y ambari-* bigtop-ambari-mpack
Bigtop Mpack を Ambari に登録します。
[azureuser@ambari ~]$ sudo ambari-server install-mpack --mpack /usr/lib/bigtop-ambari-mpack/bgtp-ambari-mpack-1.0.0.0-SNAPSHOT-bgtp-ambari-mpack.tar.gz
Using python /usr/bin/python
Installing management pack
2023-03-25 04:57:07,597 - Execute[('tar', '-xf', '/var/lib/ambari-server/data/tmp/bgtp-ambari-mpack-1.0.0.0-SNAPSHOT-bgtp-ambari-mpack.tar.gz', '-C', '/var/lib/ambari-server/data/tmp/')] {'tries': 3, 'sudo': True, 'try_sleep': 1}
Ambari Server 'install-mpack' completed successfully.
Ambari Server の setup を行い、サービスを実行します。
[azureuser@ambari ~]$ . /usr/lib/bigtop-utils/bigtop-detect-javahome
[azureuser@ambari ~]$ echo $JAVA_HOME
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.362.b08-1.el7_9.x86_64
[azureuser@ambari ~]$ sudo ambari-server setup -j $JAVA_HOME
(質問にはすべてデフォルト値で応答)
Ambari Server 'setup' completed successfully.
[azureuser@ambari ~]$ sudo systemctl start ambari-server.service
この時点で, Ambari Server の Web UI にログインできるはずです (ユーザ名・パスワードはいずれも admin です).
ambari サーバからそれ以外のサーバに、共通の秘密鍵を使って SSH でログインできるよう設定しておきましょう。また、各サーバで Ambari Agent や Hadoop の動作に必要な JDK を以下のコマンドでインストールしておきましょう。
$ sudo yum install -y java-1.8.0-openjdk-devel
ログイン後の Ambari の Web UI から作業を続けます。最初の画面で “LAUNCH INSTALL WIZARD” ボタンをクリックします。
クラスタ名の入力を促されますので、任意の名前を指定します。
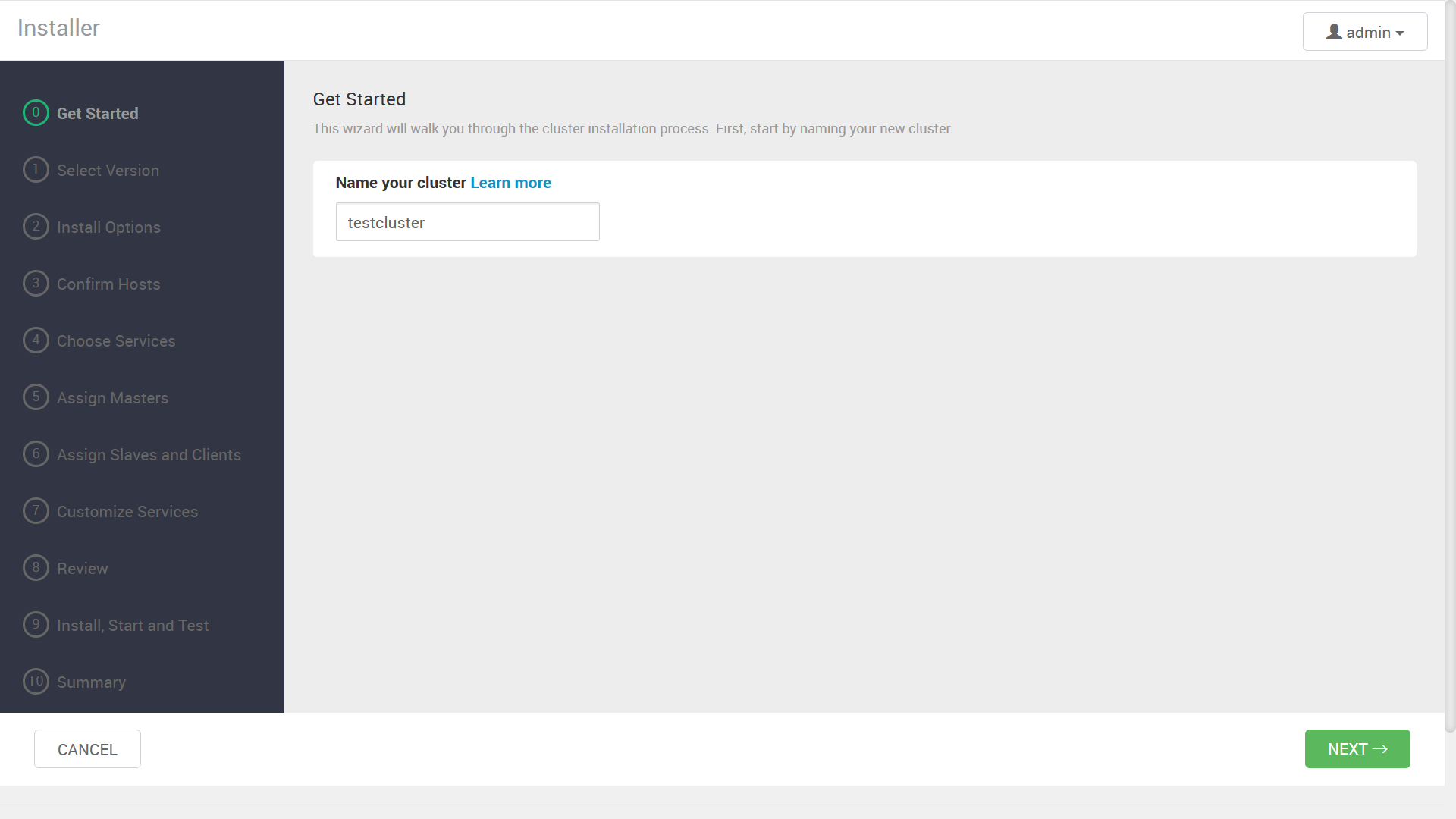
先ほど登録した Bigtop Mpack によって, Bigtop 3.2.0 ベースのソフトウェアスタックが表示されます。
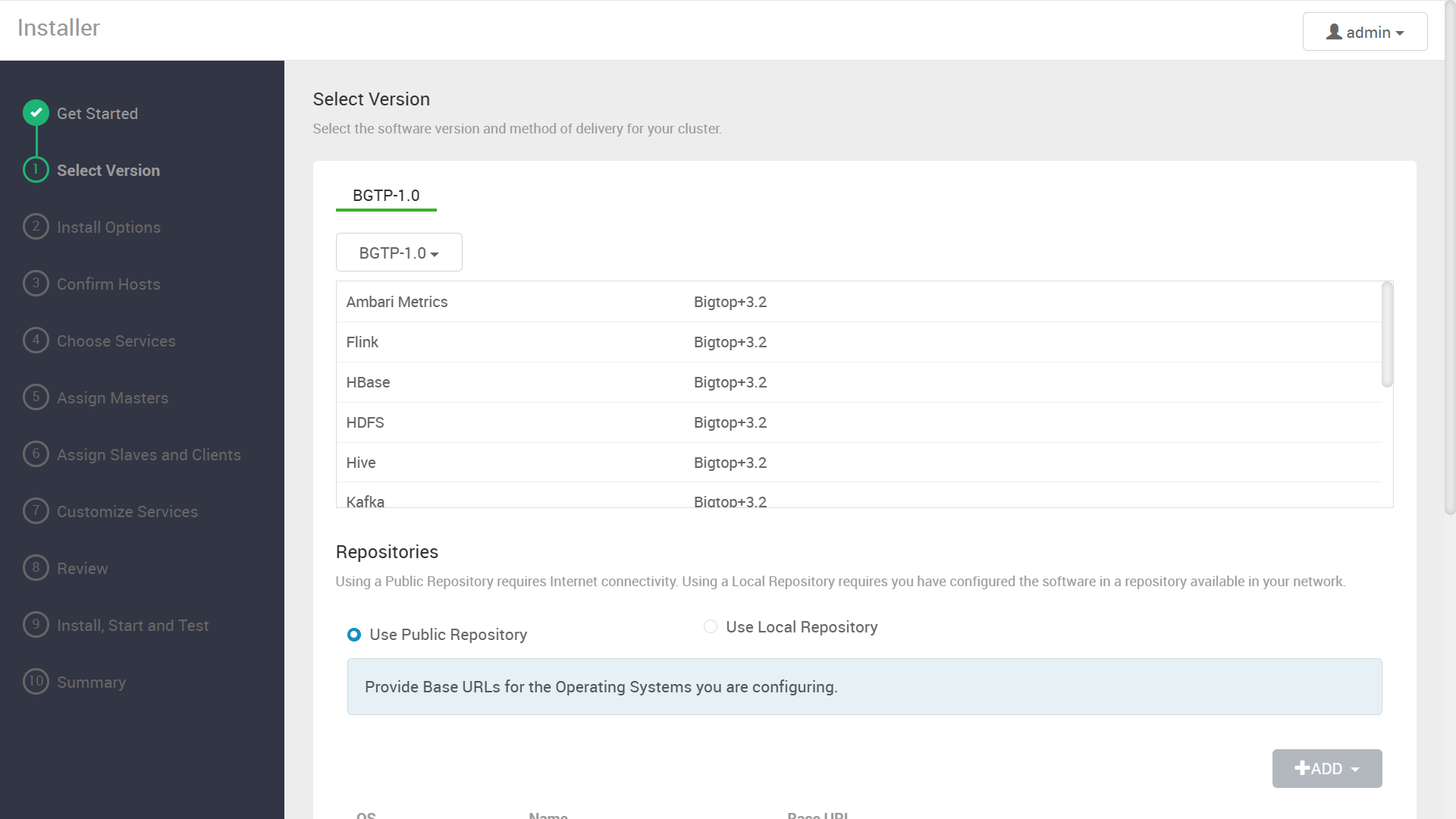
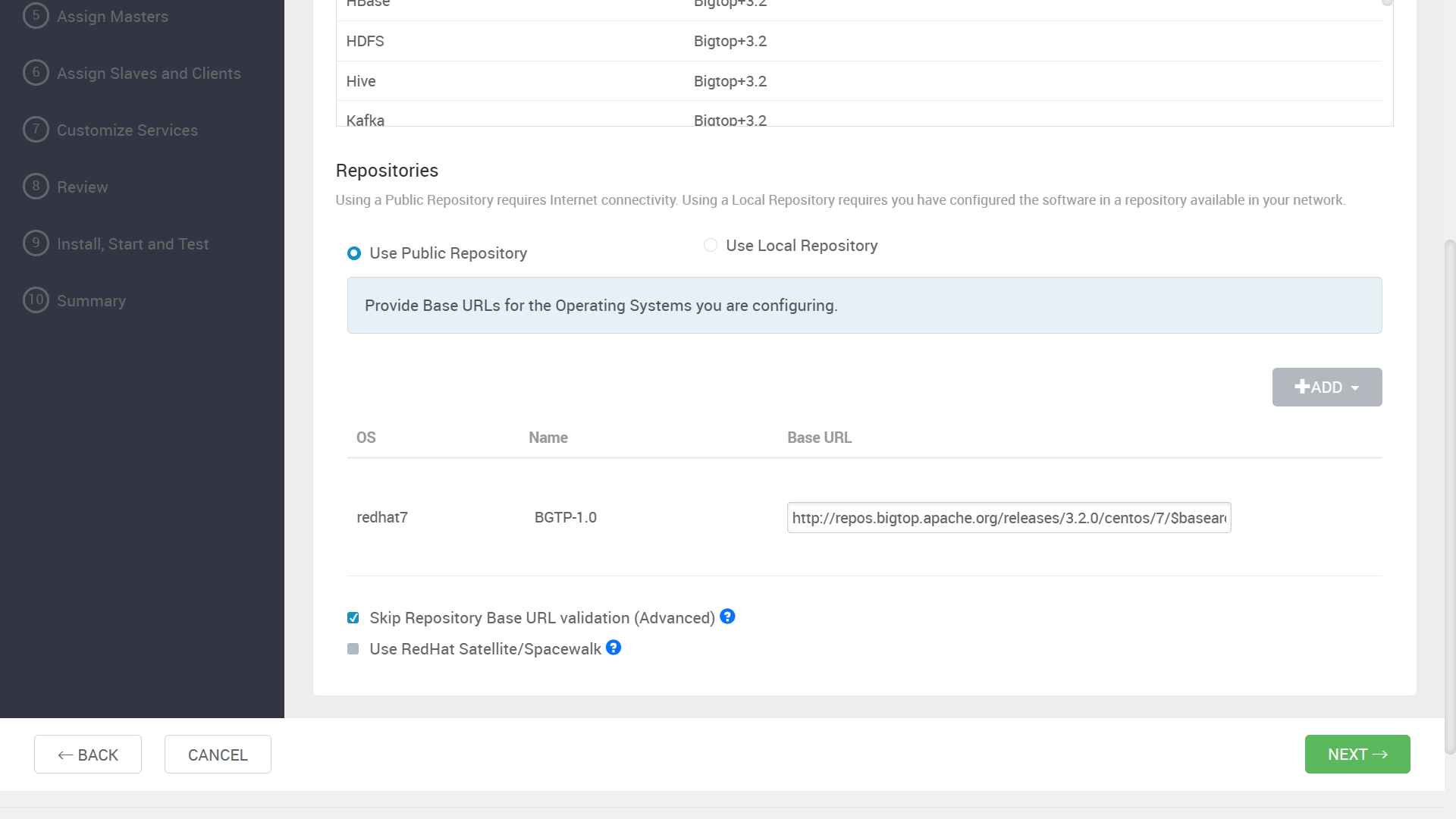
“Skip Repository Base URL validation” にチェックを入れて先に進みます。
インストール先サーバの FQDN と、それらに SSH ログインするための秘密鍵を入力します。
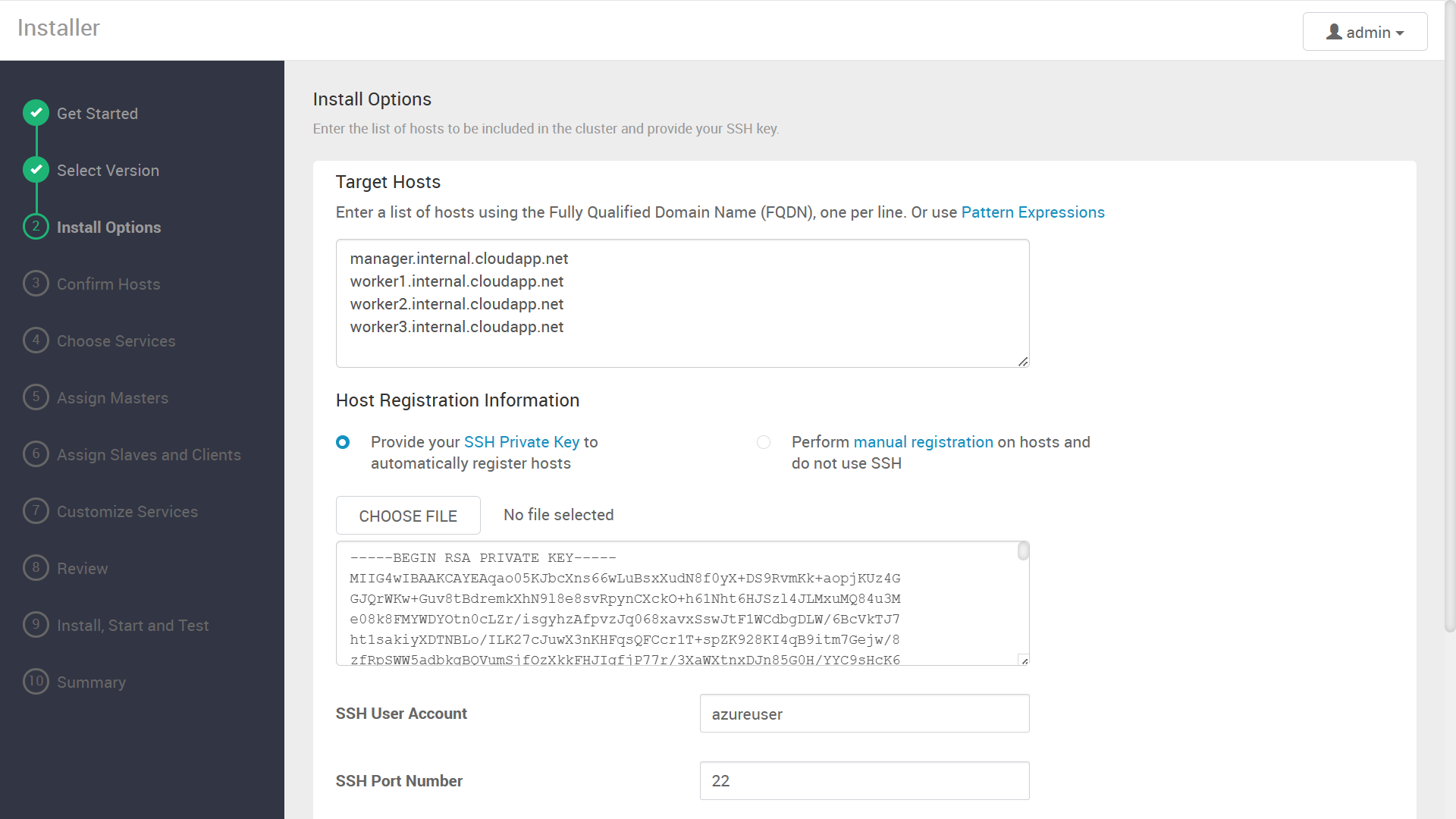
次の画面に進むと、各サーバへの Ambari Agent のインストールが開始されます。
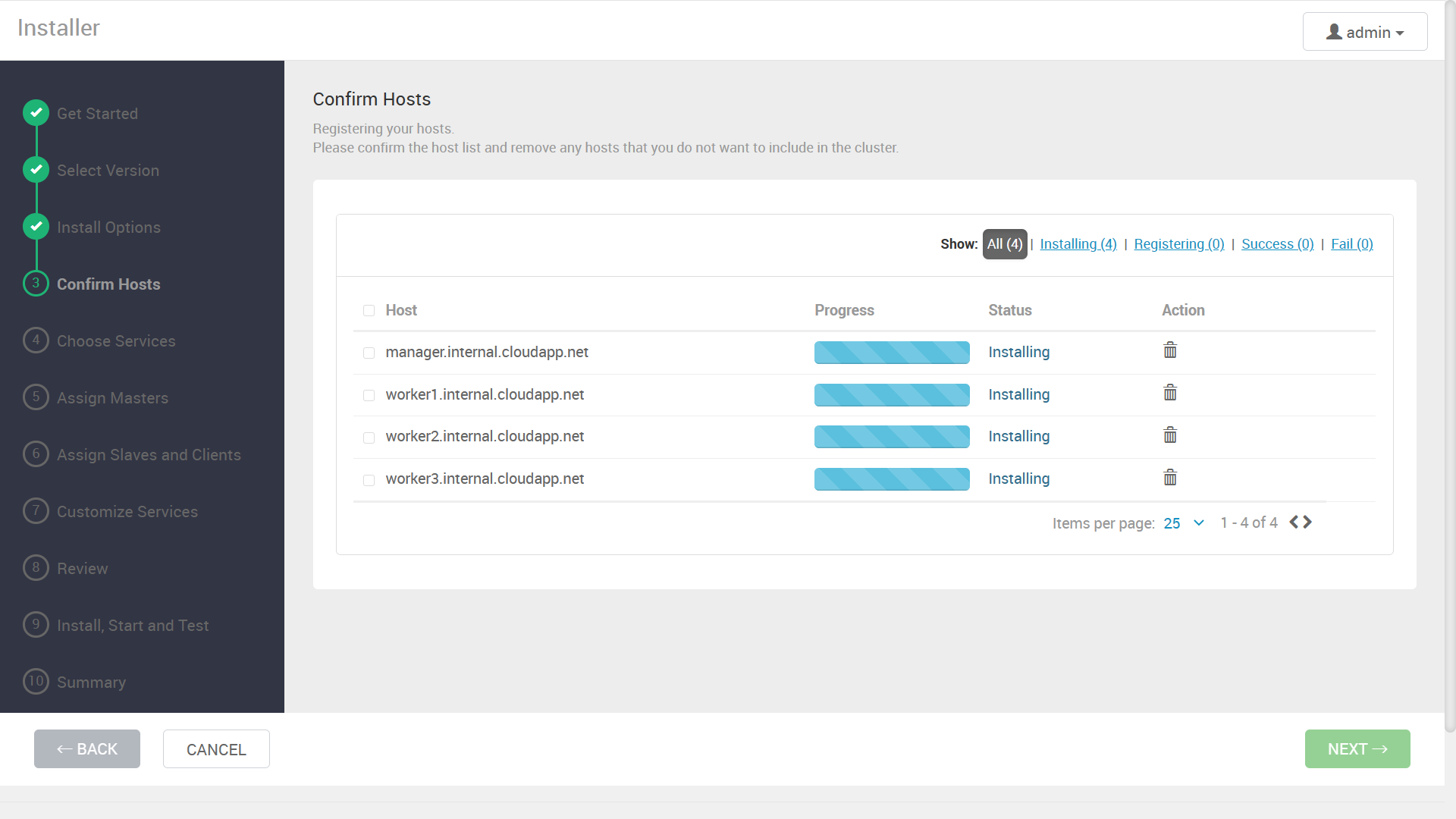
成功したら次に進みます。
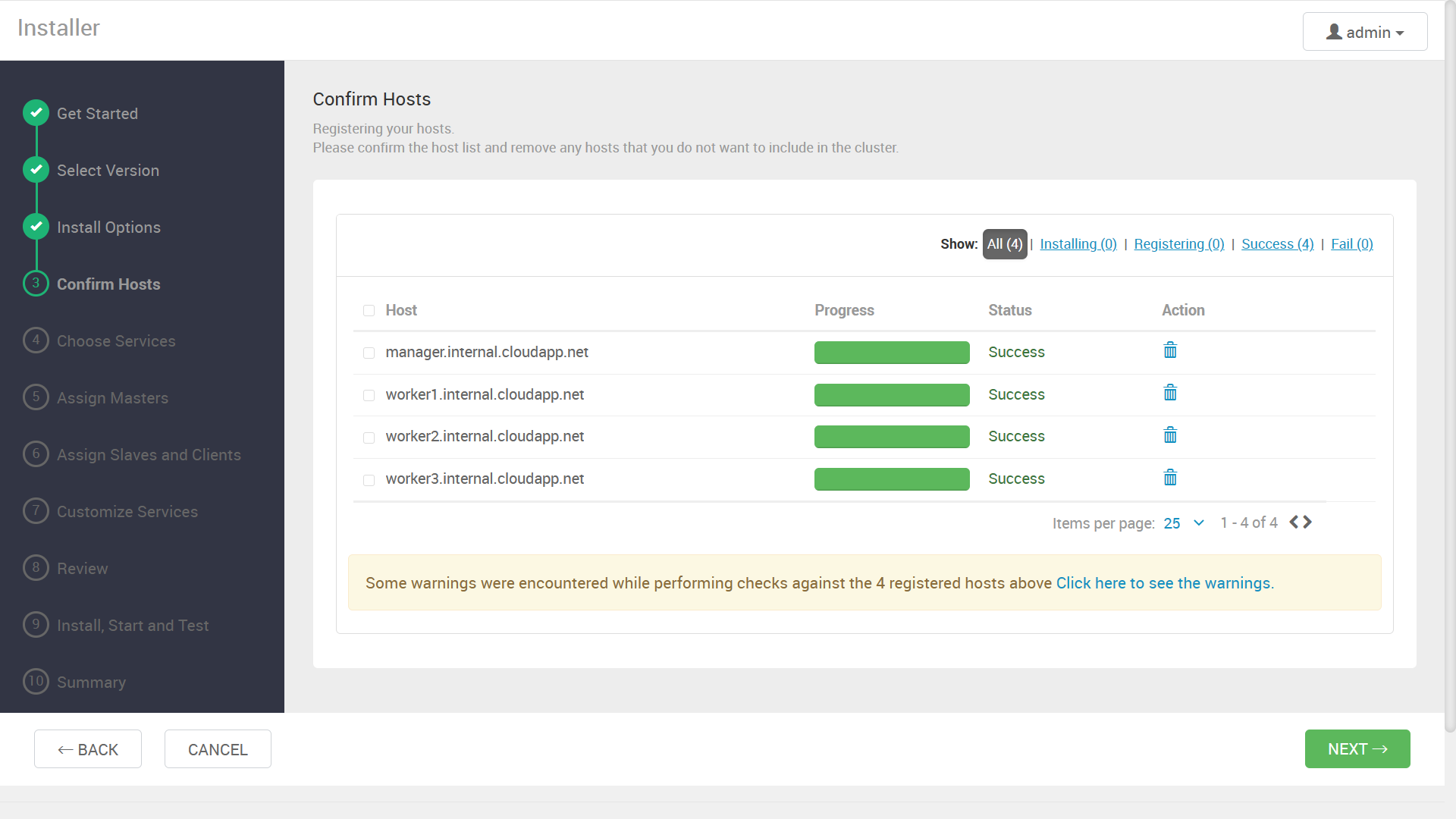
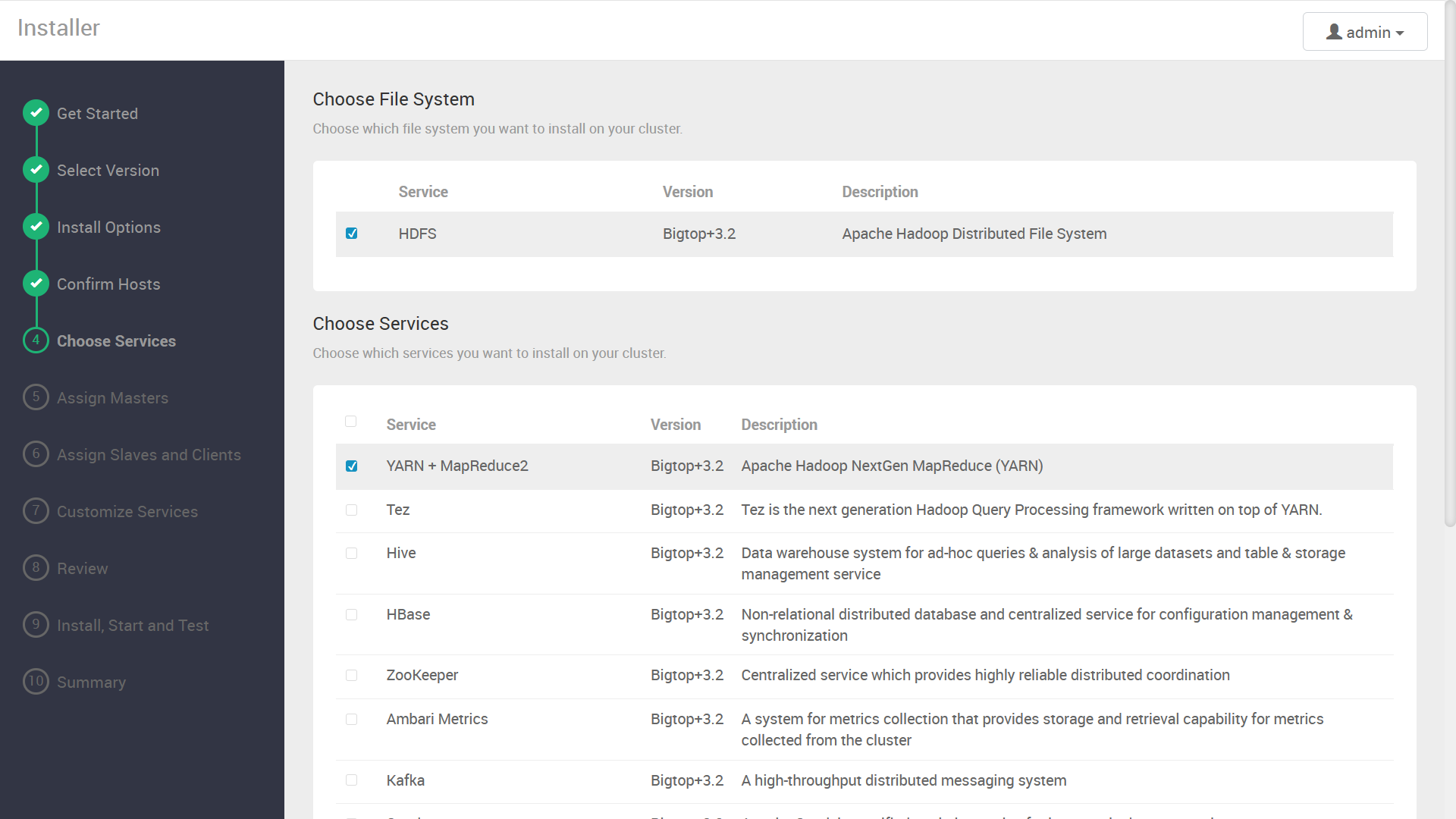
インストールするコンポーネントの選択画面が表示されます。今回は例として, ZooKeeper と Hadoop (HDFS + YARN) をインストールします。
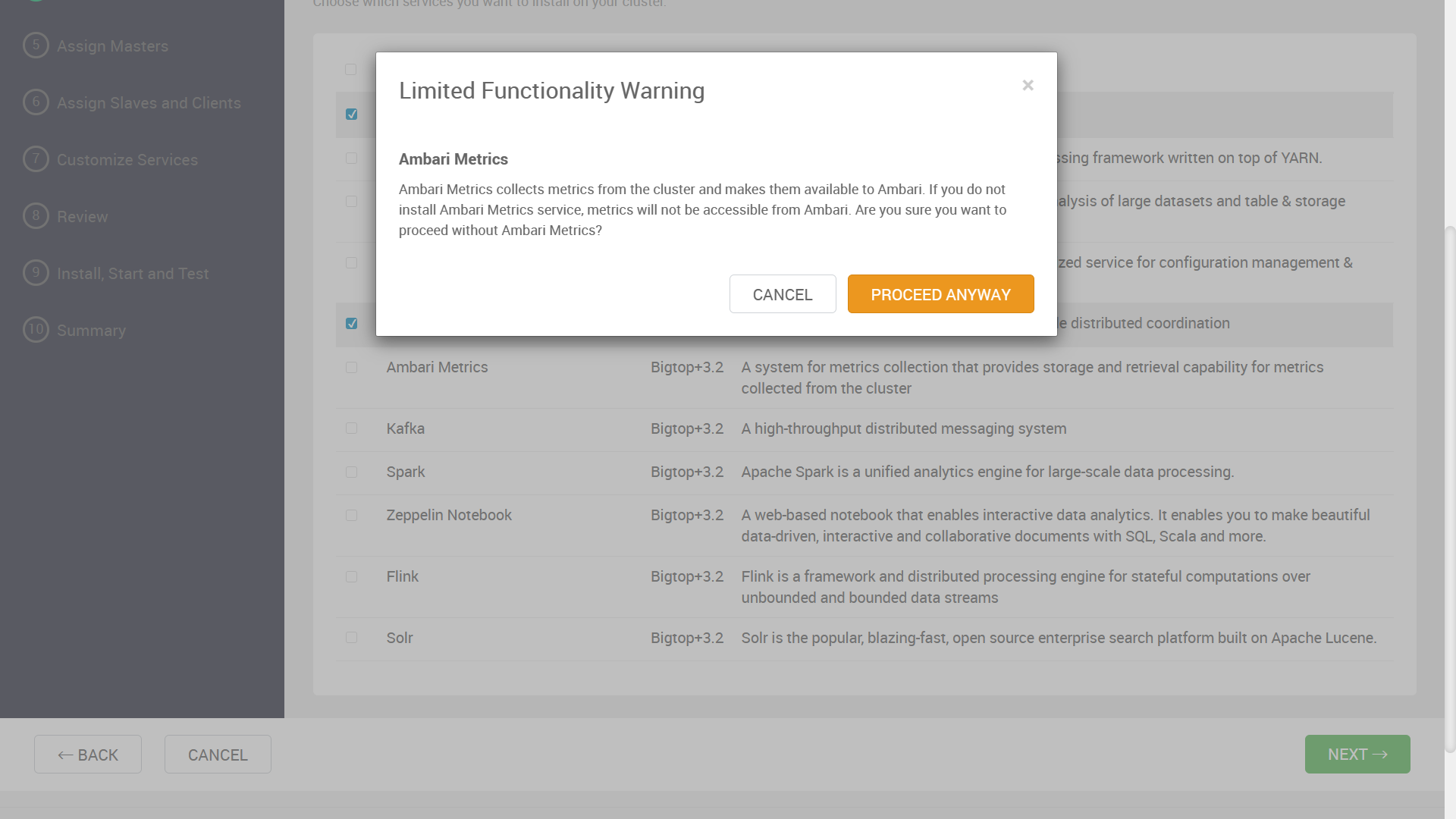
Ambari Metrics が指定されていない旨の警告が表示されますが、今回は無視します。
NameNode や ResourceManager などのサービスを、どのノードに割り当てるか指定する画面が表示されます。
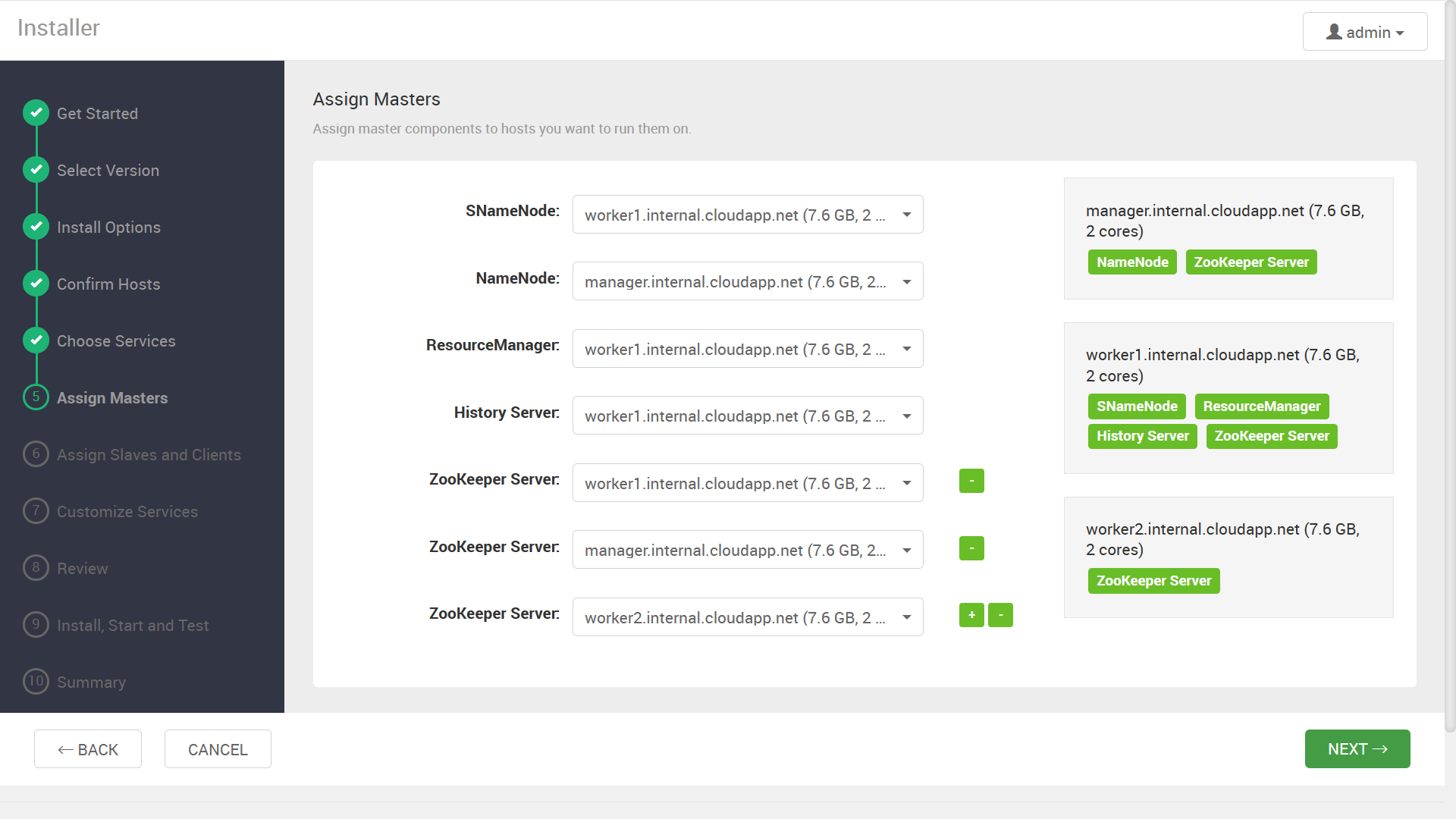
事前の設計に従い、サービスの割り当てを指定します。
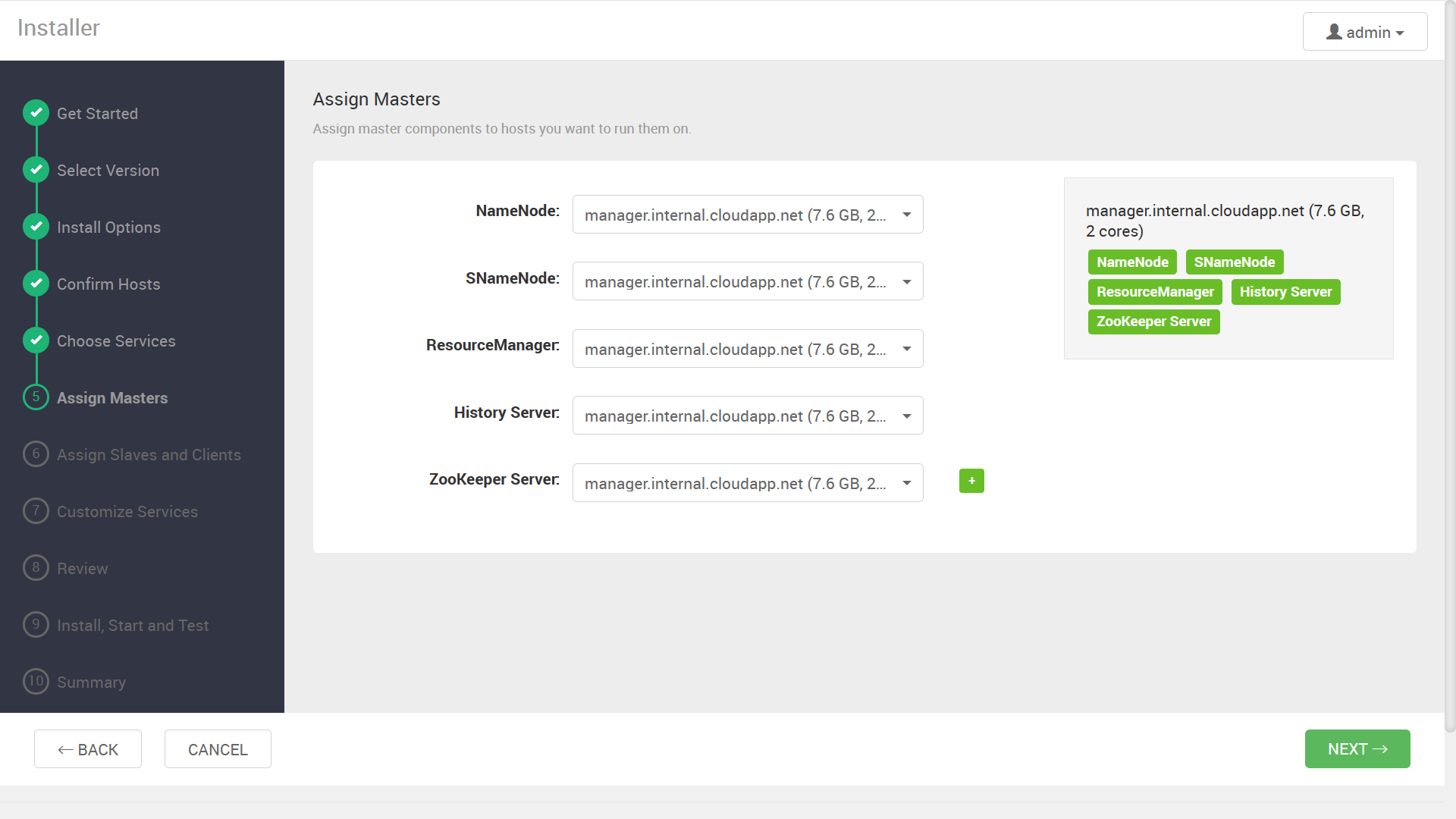
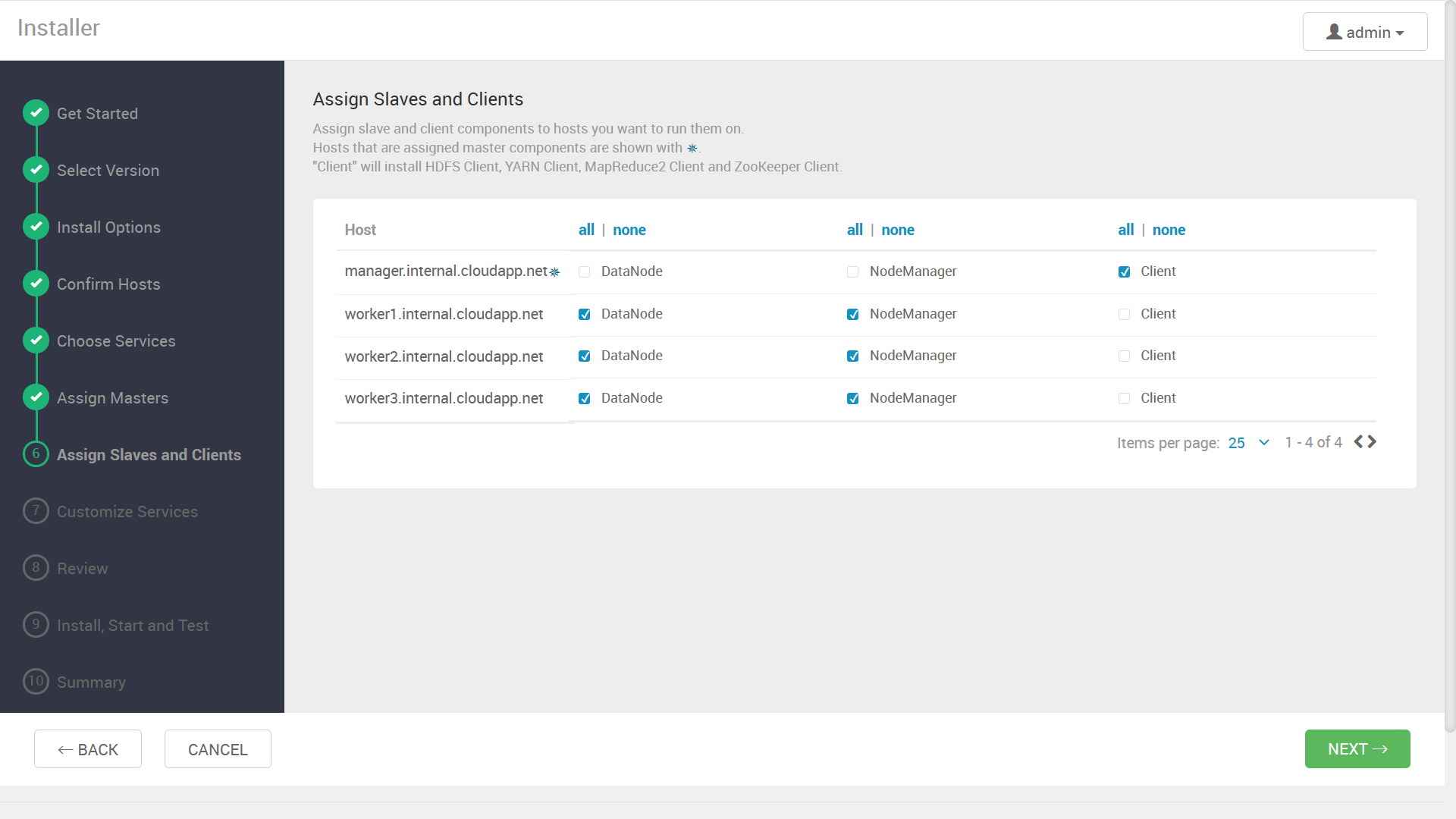
同様に、ワーカーノードやクライアントの割り当て画面が表示されるので、こちらも事前の設計に沿って指定します。
“DIRECTORIES” については、特に変更の必要はありません。
“ACCOUNTS” も同様です。
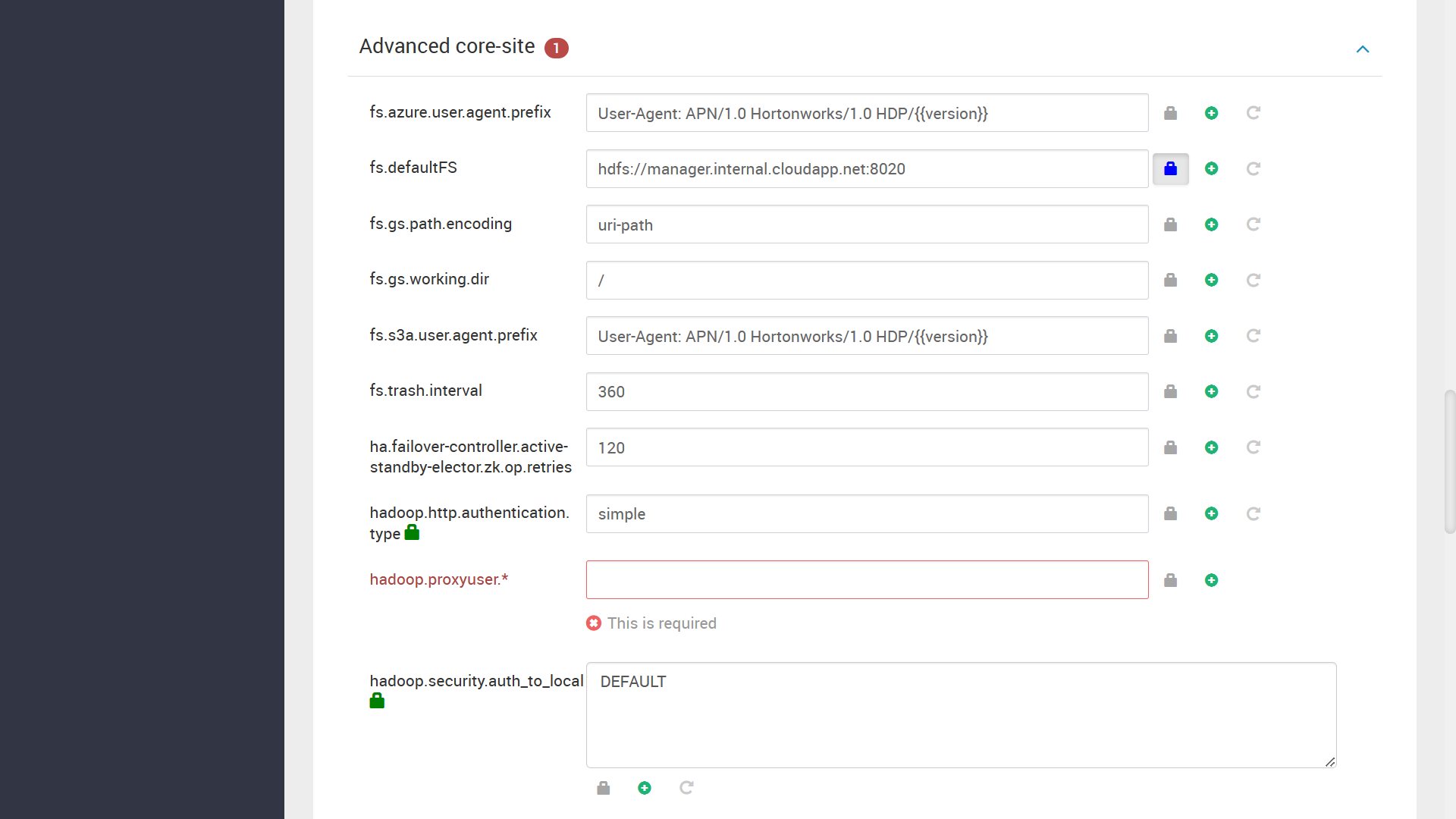
最後の configuration の設定画面で、何かエラーが出ていれば、
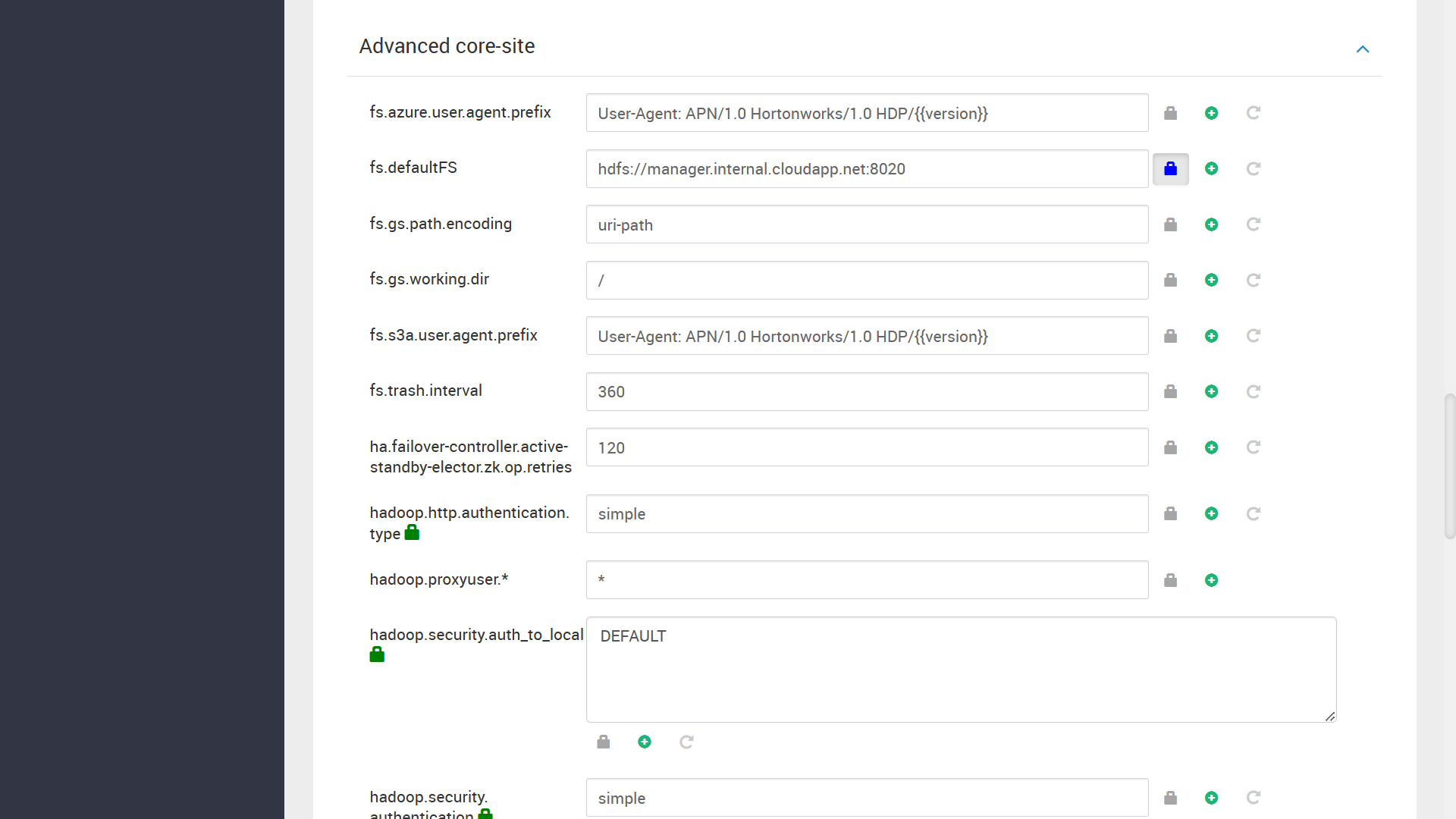
適切な値を設定し、次に進みます。
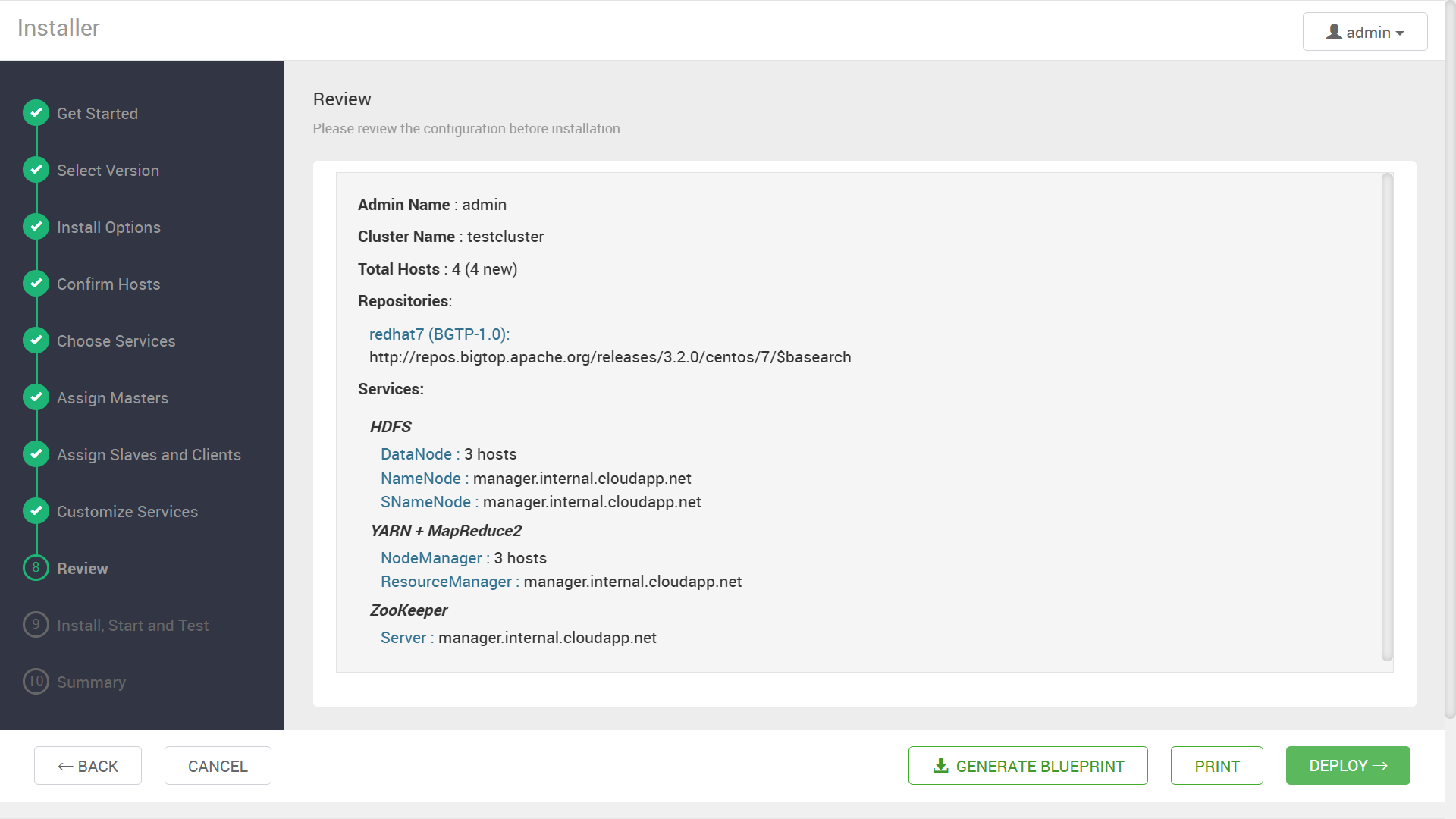
確認画面が表示されるので, “DEPLOY” ボタンをクリックしてデプロイを開始します。
成功すれば、以下のような進捗率を示した画面と、
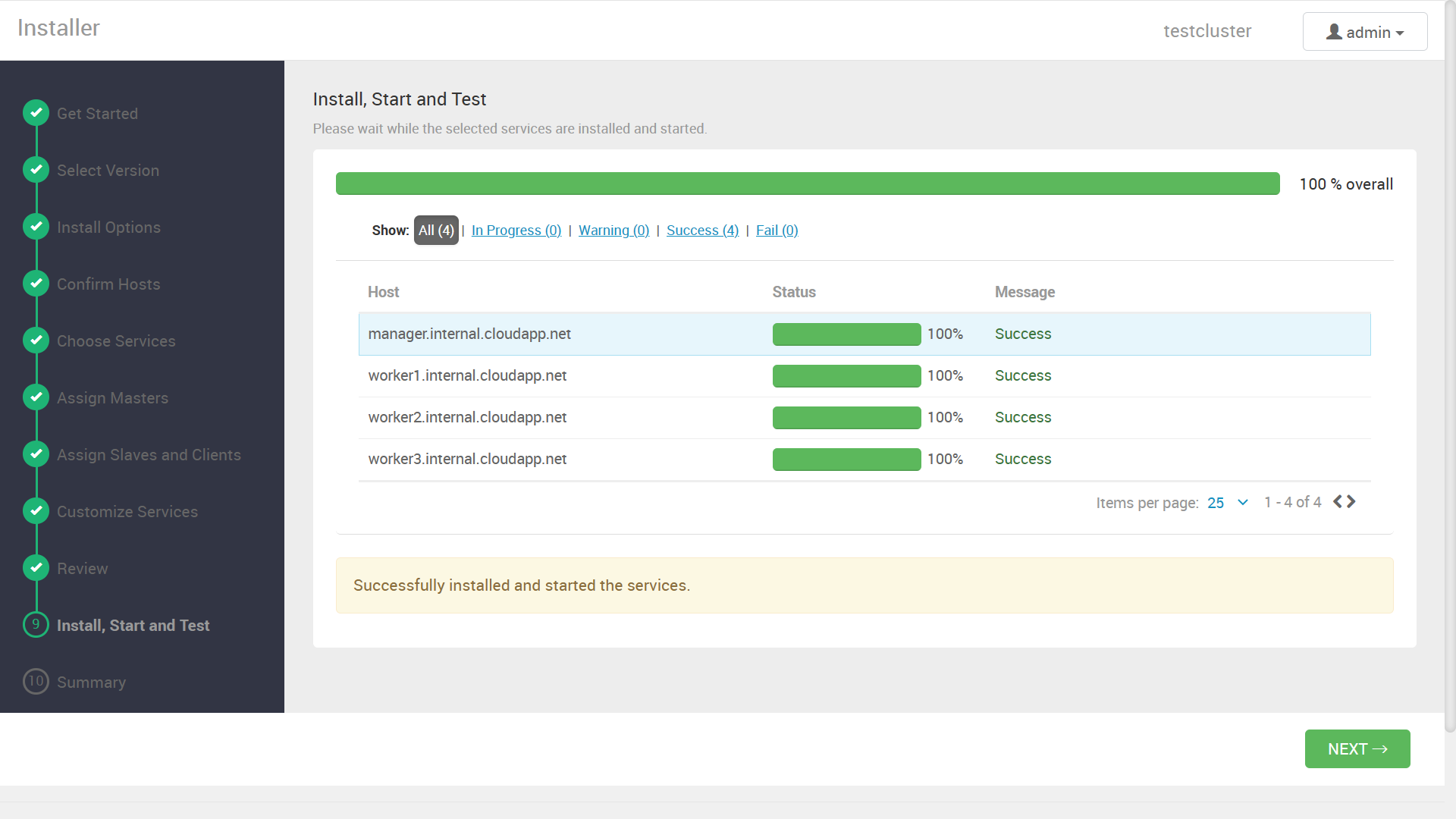
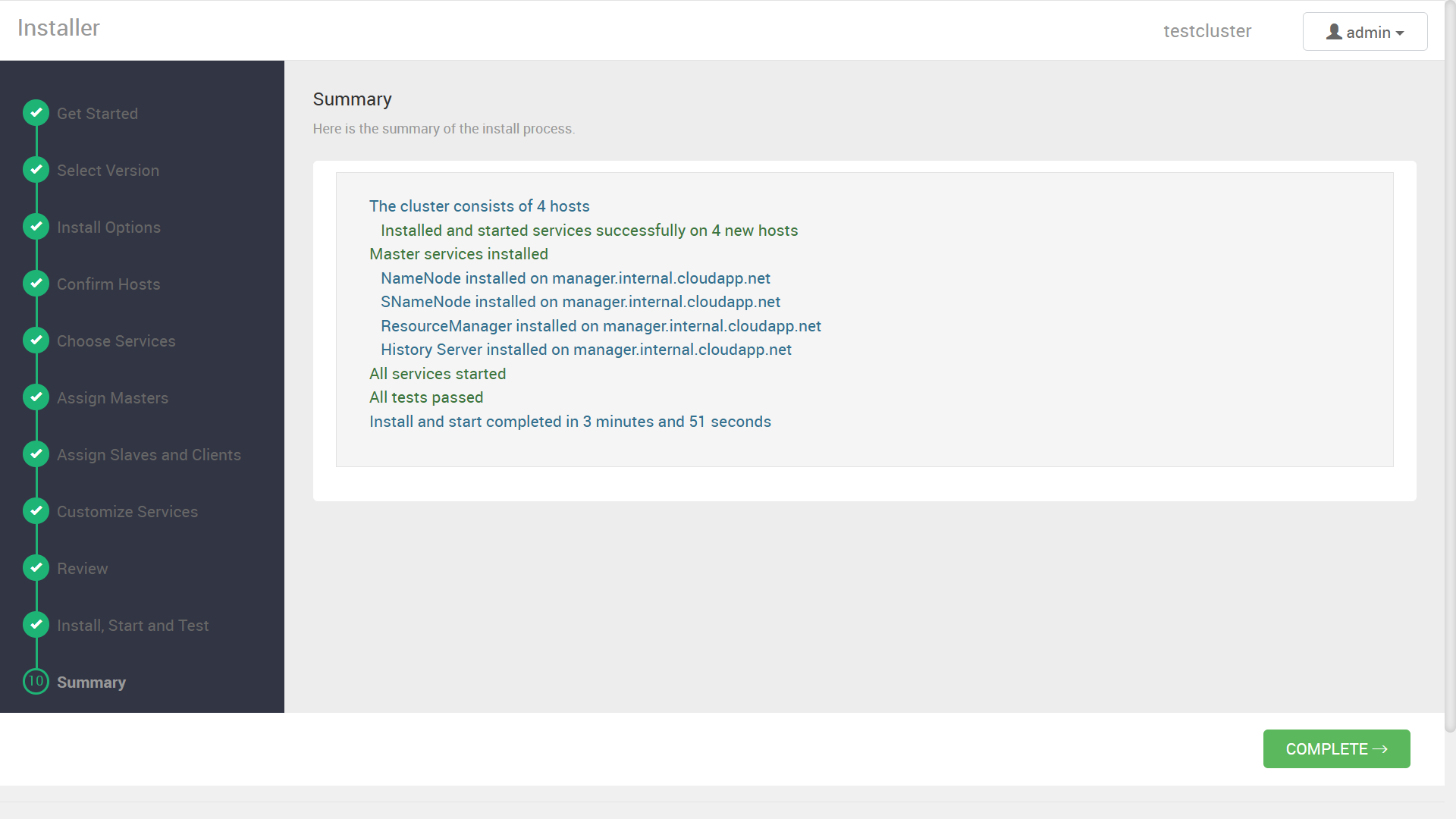
デプロイ結果のサマリ画面の後に、
Ambari のダッシュボードが正常に表示されるはずです。
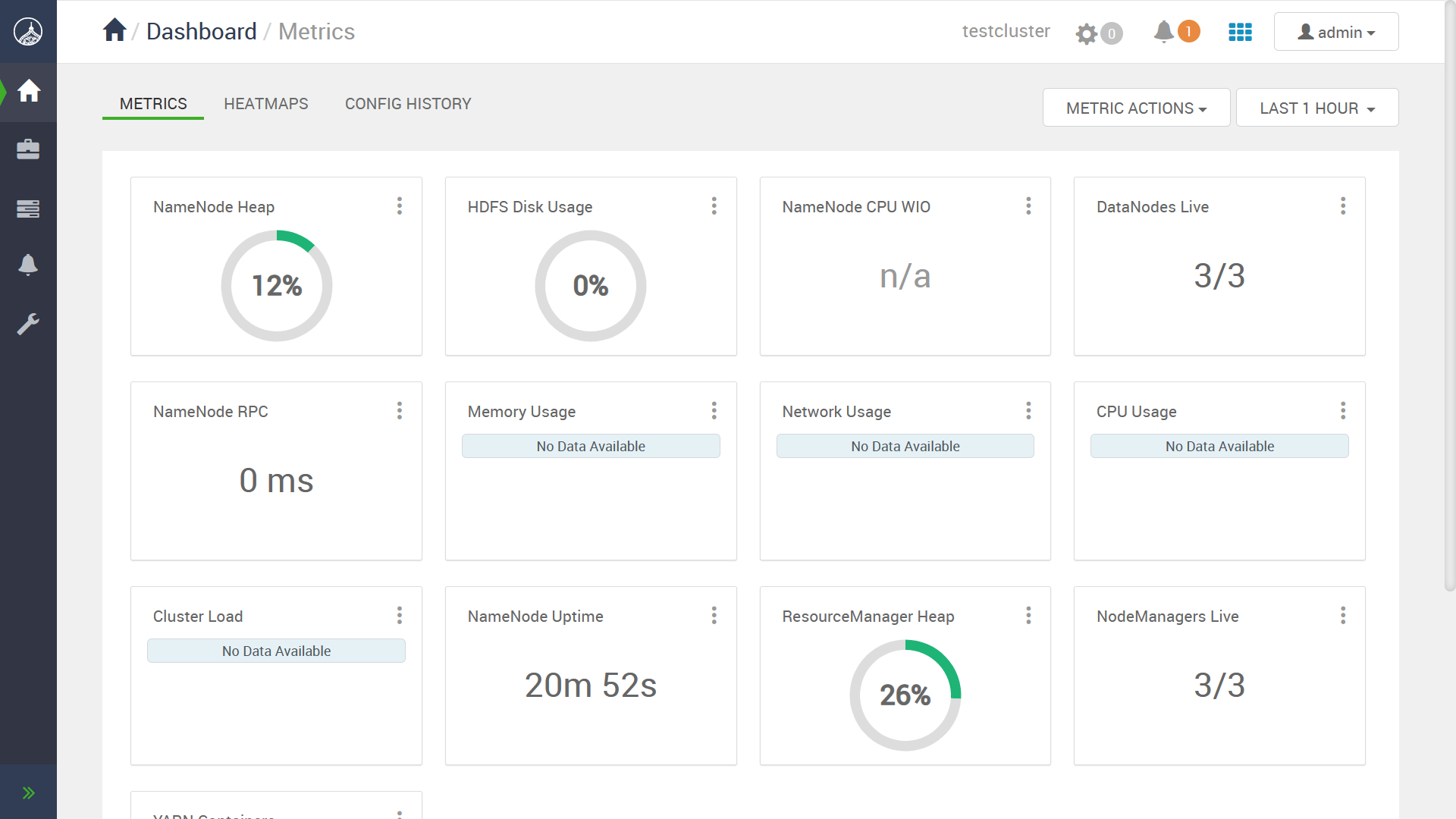
クラスタがデプロイできたので, manager サーバに SSH ログインして、サンプルの pi 計算を実行してみます。 HDFS ディレクトリのパーミッションを微修正する必要がありましたが、ジョブ自体は問題なく実行できました。
[azureuser@manager ~]$ sudo -u hdfs hdfs dfs -ls /
Found 5 items
drwxrwxrwt - yarn hadoop 0 2023-03-25 05:47 /app-logs
drwxr-xr-x - mapred hdfs 0 2023-03-25 05:47 /mapred
drwxrwxrwx - mapred hadoop 0 2023-03-25 05:47 /mr-history
drwxrwxrwx - hdfs hdfs 0 2023-03-25 05:47 /tmp
drwxr-xr-x - hdfs hdfs 0 2023-03-25 05:46 /user
[azureuser@manager ~]$ sudo -u hdfs hdfs dfs -chmod go+w /user
[azureuser@manager ~]$ sudo -u yarn yarn jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 3 1000
...
Job Finished in 21.838 seconds
Estimated value of Pi is 3.14133333333333333333
まとめ
本記事では, Bigtop 3.2.0 で可能になった, Ambari 経由での最新コンポーネントのデプロイ手順を紹介しました。 まだ CentOS 7 しかサポートしていないなど制限も多いですが、以前に比べればより新しいバージョンが利用でき、また使えるコンポーネント自体も大幅に増えましたので、条件が合う場合はぜひご活用ください。