Bigtop が提供するパッケージを使って Hadoop クラスタを構築する
本記事は, Distributed computing (Apache Spark, Hadoop, Kafka, …) Advent Calendar 2020 19日目の記事です。
この記事では, Apache Bigtop (以下 Bigtop) が提供する deb や rpm 形式のパッケージを使って、 Hadoop クラスタを構築する方法を紹介します。
想定する環境
- 1台のマスターノードと複数台のワーカーノードが存在し、全台に CentOS 7 がインストールされていること
- ノード間で相互に名前解決が可能になっていること
- 説明を単純にするため, iptables や firewalld は無効化されていること
Bigtop リポジトリの追加
まず最初に、パッケージマネージャ (今回は CentOS 7 なので yum) の設定に、Bigtop のリポジトリを追加します。 Bigtop の公式サイト を開き、 ページ中央の “Latest release” のリンク先から, “Installable binary artifacts” を選択します。
リンクを辿っていくと、以下のようなファイルの一覧が表示されます。
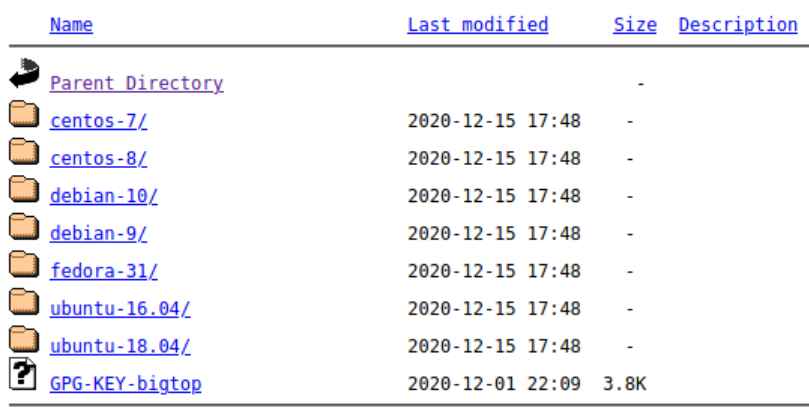
Linux ディストリビューションごとにディレクトリが分かれており、それぞれにリポジトリ情報を定義した設定ファイルが格納されています。 ですので今回は, centos-7 ディレクトリに格納されている設定ファイル bigtop.repo を取り込みます。 また、Hadoop 等の動作には JDK が必要なので、あらかじめインストールしておきます。
※全ノードで実施
$ sudo yum install -y java-1.8.0-openjdk-headless
$ sudo curl -o /etc/yum.repos.d/bigtop.repo https://downloads.apache.org/bigtop/bigtop-1.5.0/repos/centos-7/bigtop.repo
$ sudo yum update -y
HDFS の構築
それではまず HDFS を構築しましょう。マスターノードに NameNode をインストールします。
※マスターノードで実施
$ sudo yum install -y hadoop-hdfs-namenode
同様に、ワーカーノードに DataNode をインストールします。
※ワーカーノードで実施
$ sudo yum install -y hadoop-hdfs-datanode
全ノードで、NameNode/DataNode が使用するディレクトリを作成します。
※全ノードで実施
$ sudo mkdir /data
$ sudo chown hdfs:hadoop /data
また、同様に全ノードで、Hadoop の設定ファイルに以下の内容を記述します (NameNode と DataNode は同一サーバ内に同居しない想定).
$ cat /etc/hadoop/conf/core-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://(マスターノードの FQDN):9000</value>
</property>
</configuration>
$ cat /etc/hadoop/conf/hdfs-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data</value>
</property>
</configuration>
マスターノードで HDFS をフォーマットし、NameNode を起動します。
※マスターノードで実施
$ sudo -u hdfs hdfs namenode -format
$ sudo service hadoop-hdfs-namenode start
ワーカーノードで DataNode を起動します。
※ワーカーノードで実施
$ sudo service hadoop-hdfs-datanode start
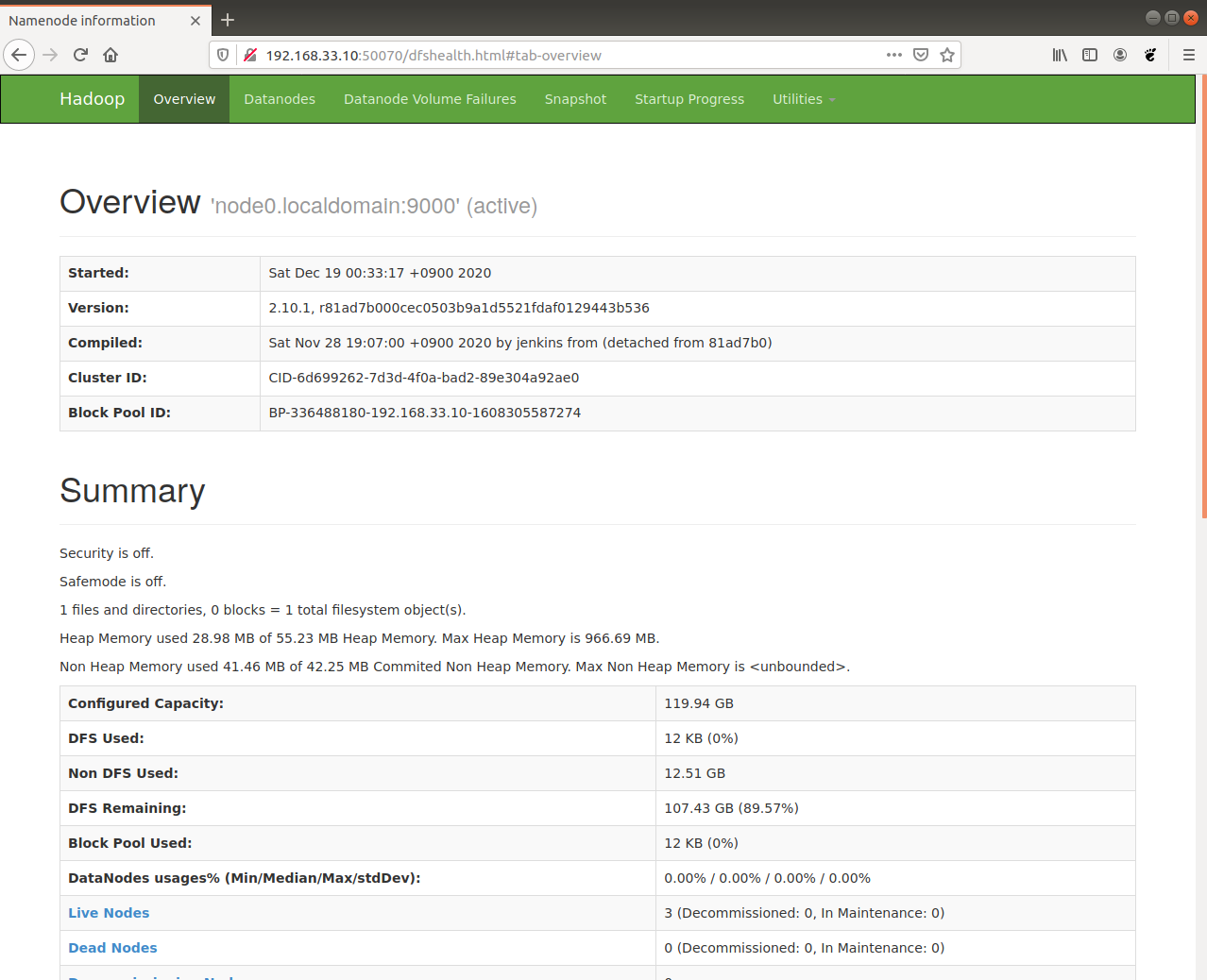
この状態でブラウザからマスターノードの 50070 番ポートにアクセスすると、管理画面が表示され HDFS が動作していることを確認できます。
YARN の構築
次に YARN をセットアップしましょう。 先ほどと同様、マスターノードに ResourceManager を、ワーカーノードに NodeManager をインストールします。 また、サンプルとして実行する MapReduce アプリケーションもインストールします。
※マスターノードで実施
$ sudo yum install -y hadoop-yarn-resourcemanager hadoop-mapreduce
※ワーカーノードで実施
$ sudo yum install -y hadoop-yarn-nodemanager hadoop-mapreduce
全ノードの yarn-site.xml, mapred-site.xml に以下の内容を記述します。
$ cat /etc/hadoop/conf/yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>(マスターノードの FQDN)</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/usr/lib/hadoop/lib/*:/usr/lib/hadoop/*:/usr/lib/hadoop-hdfs/*:/usr/lib/hadoop-hdfs/lib/*:/usr/lib/hadoop-yarn/lib/*:/usr/lib/hadoop-yarn/*:/usr/lib/hadoop-mapreduce/lib/*:/usr/lib/hadoop-mapreduce/*</value>
</property>
</configuration>
$ cat /etc/hadoop/conf/mapred-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
また、サンプルの MapReduce ジョブを実行するのに必要な HDFS 上のディレクトリを作成し、適切な権限を付与します。
※任意の1ノードで実施
$ sudo -u hdfs hdfs dfs -mkdir /tmp
$ sudo -u hdfs hdfs dfs -chgrp hadoop /tmp
$ sudo -u hdfs hdfs dfs -chmod 777 /tmp
$ sudo -u hdfs hdfs dfs -mkdir -p /user/yarn
$ sudo -u hdfs hdfs dfs -chown yarn:hadoop /user/yarn
$ sudo -u hdfs hdfs dfs -chgrp hadoop /user
マスターノードで ResourceManager を、ワーカーノードで NodeManager を開始します。
※マスターノードで実施
$ sudo service hadoop-yarn-resourcemanager start
※ワーカーノードで実施
$ sudo service hadoop-yarn-nodemanager start
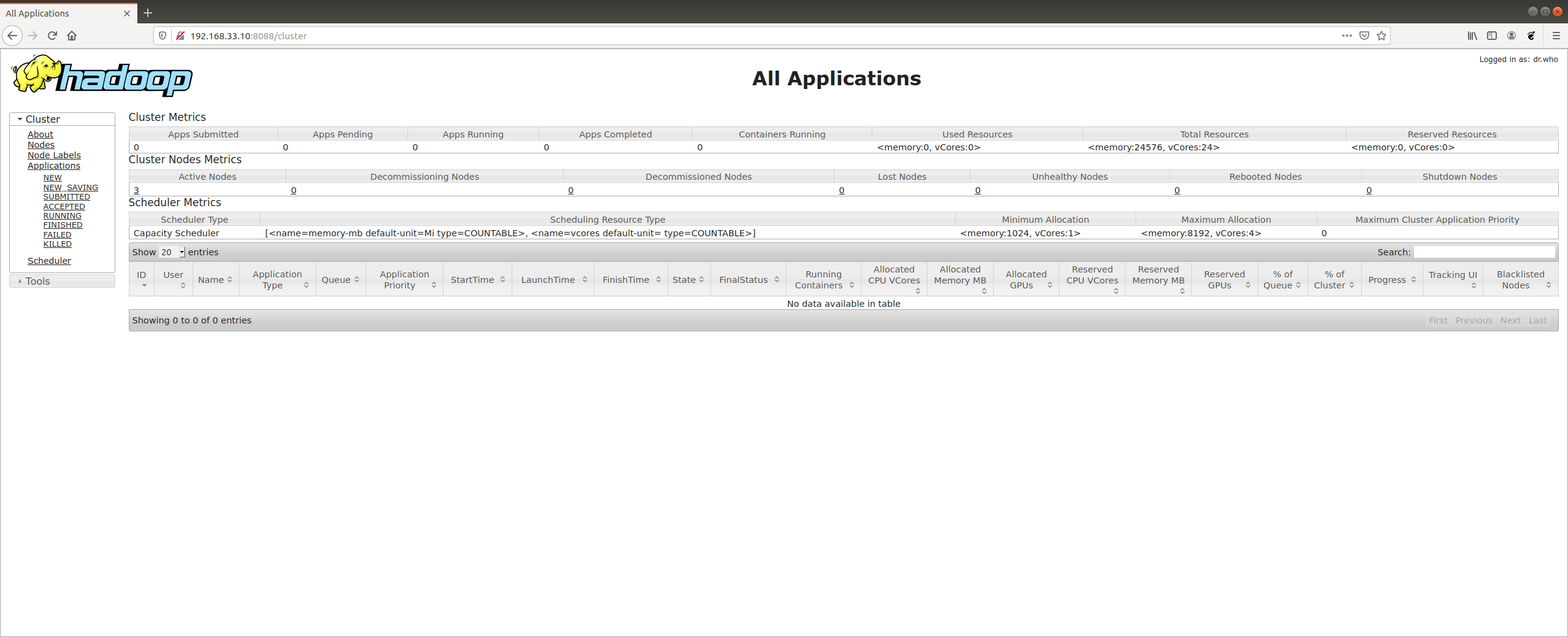
ブラウザからマスターノードの 8088 番ポートにアクセスすると, YARN サービスが実行中であることが確認できます。
いくつかサンプルの MapReduce ジョブを実行し、正常に終了することを確認しましょう。
$ sudo -u yarn yarn jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 3 1
(略)
Job Finished in 52.318 seconds
Estimated value of Pi is 4.00000000000000000000
$ sudo -u hdfs hdfs dfs -mkdir /tmp/input
$ sudo -u hdfs hdfs dfs -put /etc/hadoop/conf/* /tmp/input
$ sudo -u yarn yarn jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar wordcount /tmp/input /tmp/output
(略)
20/12/18 15:52:51 INFO mapreduce.Job: map 100% reduce 100%
20/12/18 15:52:51 INFO mapreduce.Job: Job job_1608306299103_0002 completed successfully
(略)
$ sudo -u hdfs hdfs dfs -cat /tmp/output/* | sort -k2 -nr | head
# 323
the 257
to 147
of 128
is 111
for 105
and 82
The 80
a 80
by 74
まとめ
以上のように, Bigtop リポジトリを利用することで、 前回の記事 で挙げたコンポーネント群を、依存関係も含めて容易にインストールすることができます。
なお, CentOS 7 以外の Linux ディストリビューションでも、作業の流れは同じです。以下の点にのみご注意ください。
-
CentOS 8 や Fedora 31 の場合、yum コマンドの代わりに dnf コマンドをご使用ください (実際には yum コマンドでも成功すると思いますが、お作法として…).
-
Debian 9/10 や Ubuntu 16.04/18.04 の場合, JDK のパッケージ名が変わること (openjdk-8-jdk-headless), yum コマンドの代わりに apt コマンドを使うことに加えて、 リポジトリ定義ファイル (Debian 系の場合 bigtop.repo) の登録時に 以下のコマンドも実行し、Bigtop 開発者の GPG 公開鍵を取り込んでください (その後の deb ファイルの署名の検証に使われます).
$ curl https://downloads.apache.org/bigtop/bigtop-1.5.0/repos/GPG-KEY-bigtop | sudo apt-key add -